如何用Python自编k-近邻算法?

k-近邻算法概述
简单地说,kNN依据不同特征值之间的距离进行分类。它不具有显式的学习过程,实际上是利用训练数据集对特征向量空间进行划分,并作为其分类的模型,即我们知道训练集中每一数据与所属分类的对应关系,输入没有标签的新数据后,将新数据的每个特征与训练集中数据对应的特征进行比较,然后算法提取训练集中特征最为相似数据的分类标签,选择k个最相似数据中出现次数最多的类别作为新数据的分类。
自编kNN函数
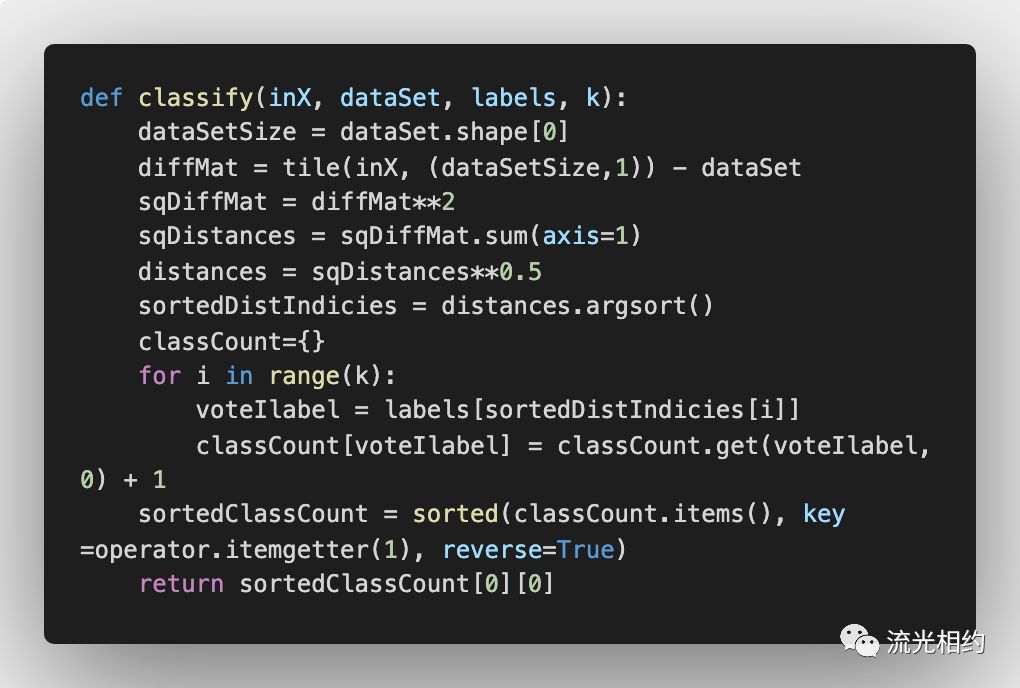
classify() 函数有 4 个输入参数:待分类的输入向量 inX ,训练集 dataSet,训练集标签向量 labels,参数 k 为选择最近数据点个数,其中,inX 维度为 1*N,dataSet 维度为 M*N,labels 维度为 1*M,k 为奇数。
dataSet.shape 以元组形式返回训练集维度 (M, N),dataSetsize 为训练集的样本个数 M。这里距离度量采用欧式距离,因而 tile 函数将输入数据重复 M 行 1 列(从而与训练集维度相同),分别和训练集中的每个数据点对应特征相减再平方,再按行相加,不保持其二维特性,即得输入数据与训练集中每个数据点之间的欧式距离。
计算完距离之后,argsort 函数对距离按照从小到大的次序排列,并返回排序后对应的原始索引值。使用 for 循环确定前 k 个距离最小元素所属的类别 voteIlabel,使用 get 函数按照字典 classCount 键值取得相应的字典值,如果字典中存在这个键,get 函数就返回对应的字典值,如果不存在,则返回 0,用这种方式计数 k 个数据中每个标签出现的次数。因而字典 classCount 中键值为标签,字典值为 k 个标签对应的个数。
使用 sorted 函数对字典 classCount 进行排序:items 函数同时引用字典的键和值,结果是一个列表,其中包含的是键-值对形式的元组。由于字典没有隐含排序,我们可以按照字典的键或字典值来排序,这里的 key 就是排序的规则,关键字函数设置用于排序的关键字。使用 operator 模块中的 itemgetter 函数对列表按照每个元组第二个索引位置(即字典值,标签个数)进行排序,reverse=True 对应降序。所以最后返回 sortedClassCount 列表中第一个元组的第一个值,即在 k 个标签中出现次数最多的标签,这样即完成了一个简单的 kNN 算法。
创建训练集
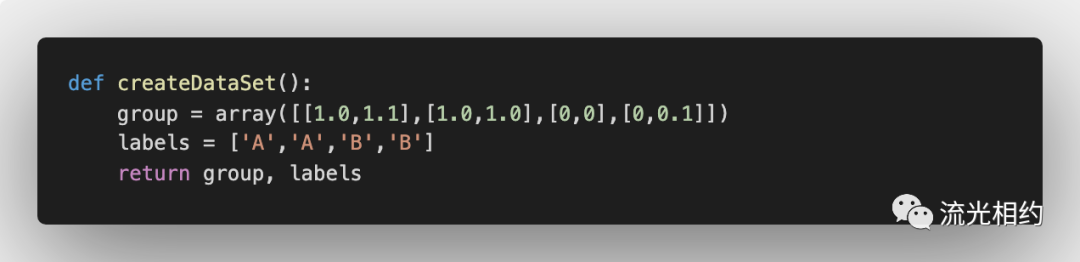
我们创建了一个简单的训练集,有 4 组数据,每组数据有两个我们已知的属性/特征值。向量 labels 包含了每个数据的标签信息,labels 包含的元素个数等于 group 矩阵行数。
运行kNN
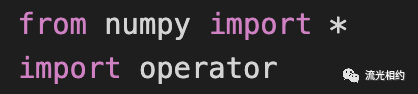
我们需要在脚本中导入两个模块 NumPy 和运算符 operator(kNN 执行排序操作时使用到):
保存脚本文件,改变当前路径到存储脚本文件位置,进入 Python:

输出结果应该是 B,也可以改变输入数据运行。这样,我们已经构造了一个简单的 kNN 分类器。