kNN改进约会网站的配对效果

前言
前面我们已经初步了解了kNN——如何用Python自编k-近邻算法?今天我们试着进行一个实例上kNN的应用。
海伦一直使用在线约会网站寻找自己心仪的约会对象。经过一番总结,她发现曾交往过三种类型的人:不喜欢的人、魅力一般的人和极具魅力的人。她发现自己无法直接将约会网站推荐的匹配对象归入恰当的上述类别之中,希望我们的分类软件能够更好地帮助她进行确切的分类。此外,她还收集了一些约会网站未曾记录的数据信息,提供给了我们。
准备数据:从文本文件中解析数据
海伦将准备的数据存放在文本文件datingTestSet2.txt中,每个样本数据占据一行,总共有1000行。每个样本主要收集了3种特征:每年飞行里程数、玩视频游戏所耗时间百分比和每周消费的冰淇淋公升数。如下:
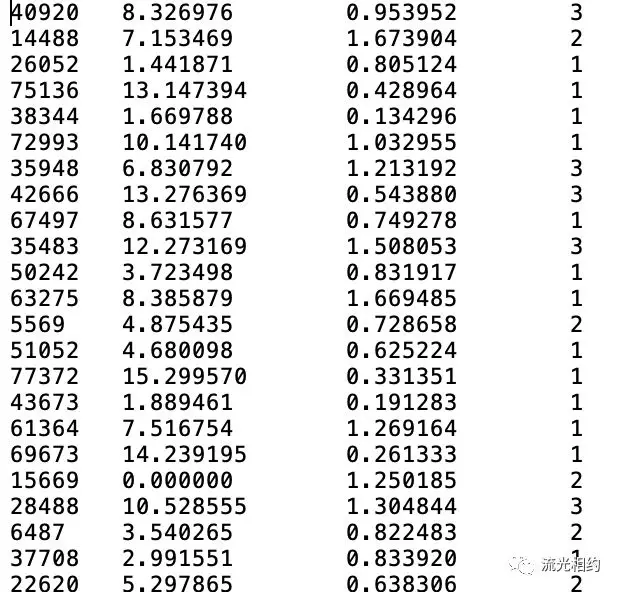
而在我们将上述特征数据输入到分类器之前,必须将待处理数据的格式转换为分类器可以接受的格式。我们之前在kNN.py中已经创建了kNN分类器函数,接下来我们创建用于处理输入数据格式的file2matrix函数,此函数的输入为文件名字符串,输出为训练样本矩阵和类标签向量,将文本记录转换为NumPy。
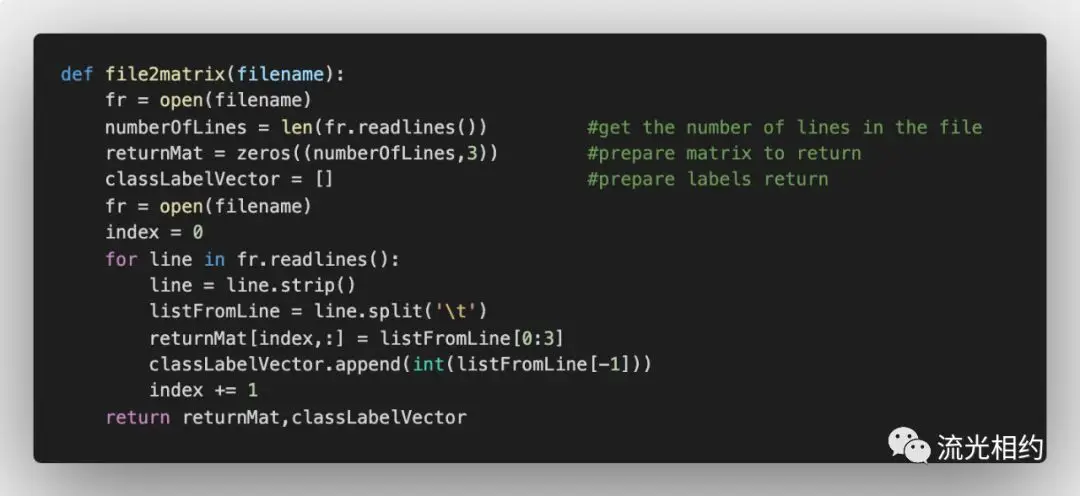
首先我们以r模式(只读模式)打开要处理的文本文件,readlines函数读取整个文件所有行,保存在一个列表变量中,每行作为一个元素,我们计数文件的行数。然后创建以零填充的矩阵,我们将该矩阵的另一维度设置为固定值3。循环处理文件的每一行数据:使用strip函数截取掉所有的回车字符,使用tab字符(将上一步得到的整行数据分割成一个元素列表,选取前3个元素存储到特征矩阵中,使用索引值-1将文件的最后一列存储到向量classLabelVector中,这里,我们必须明确地通知解释器存储的的元素值为整型,否则Python会将这些元素当作字符串进行处理。
使用函数file2matrix读取文件数据,必须确保文件存储在我们的工作目录中。重新加载kNN.py模块,以确保更新的内容可以生效,否则Python将继续使用上次加载的kNN模块。
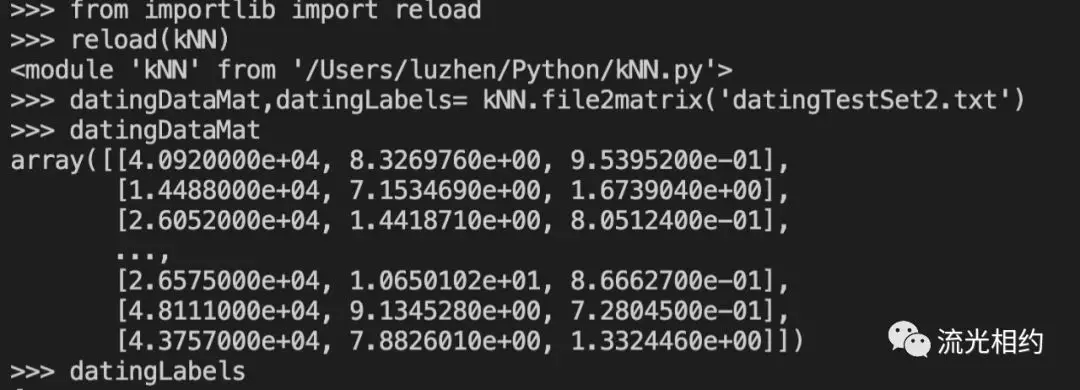
现在我们已经从文本文件导入了数据并将其格式化为想要的格式,接下来我们以图形化的方式直观地展示数据内容,以便辨识出一些数据模式。
分析数据:使用Matplotlib创建散点图
首先我们使用Matplotlib制作原始数据的散点图:
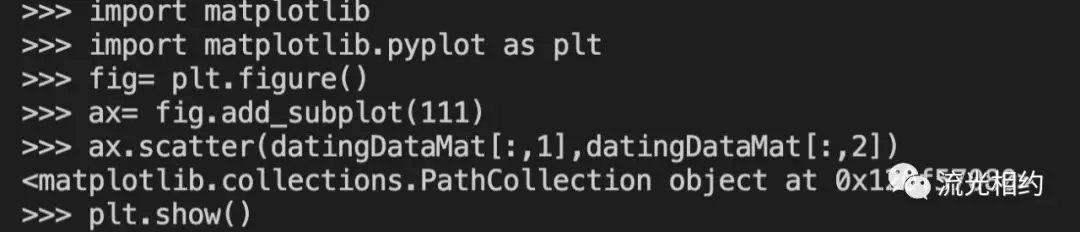
输出效果如下图,散点图使用特征矩阵的第二、三列数据,分别为玩视频游戏所耗时间百分比和每周消费的冰淇淋公升数。由于没有使用样本类别标签,我们很难看出有用的数据模式信息。
为了更好地理解数据,我们以不同的方式来标记不同的样本类别。Matplotlib库提供的scatter函数支持个性化标记散点图上的点。重新输入上面的代码,调用scatter函数时使用下列参数,利用变量datingLabels存储的类别标签属性,在散点图上绘制色彩不等、尺寸不同的点:

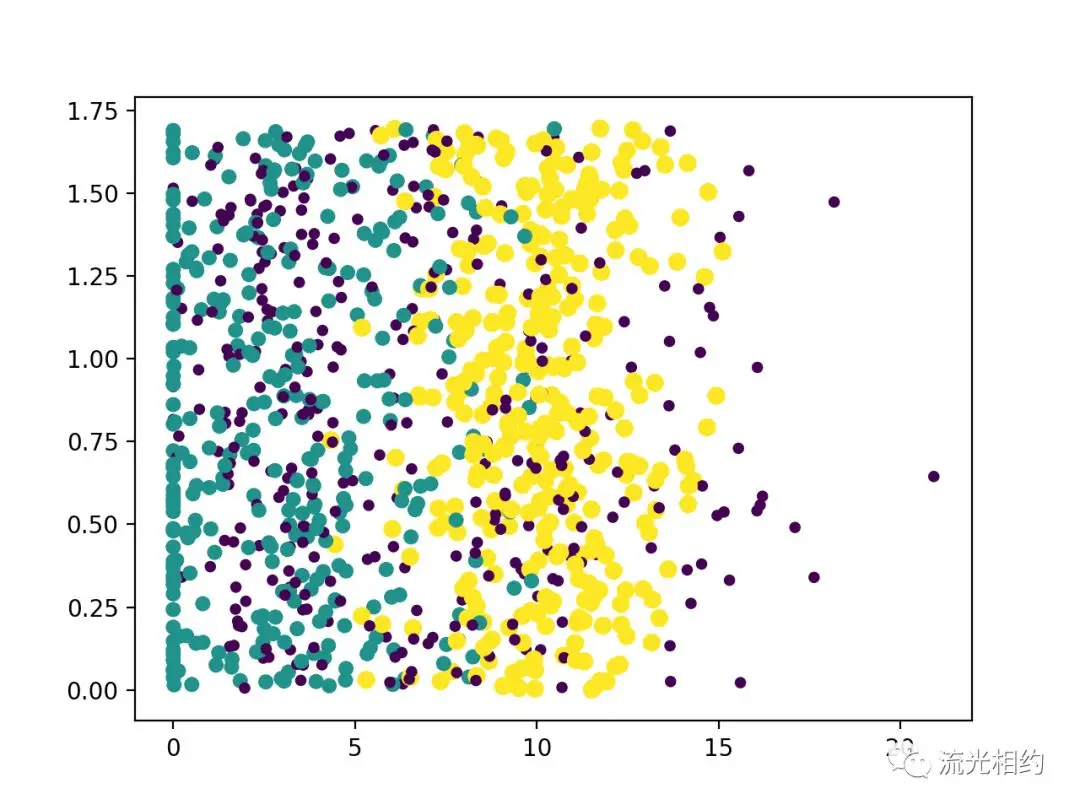
我们基本上能够看到数据点所属三个类别的区域轮廓,但还不是十分明显,接下来我们使用特征矩阵的第一、二列属性作图:
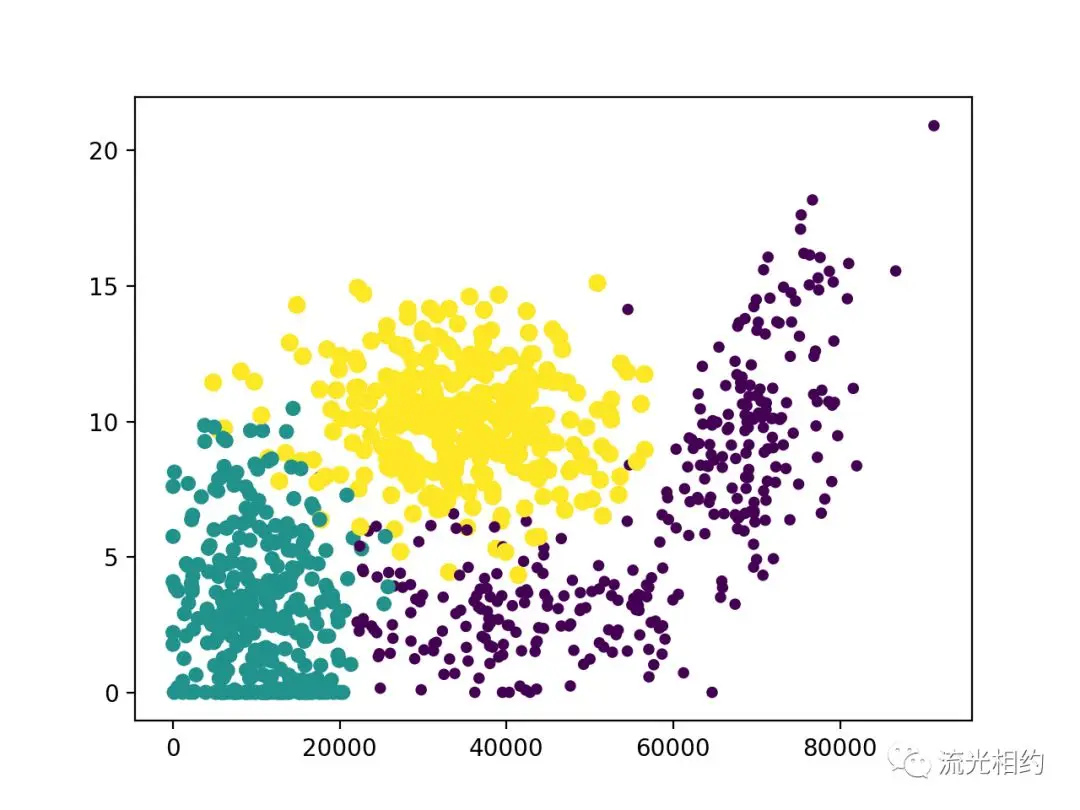
此时我们可以看到图中清晰地标示了三个不同的样本类别区域,通过这两个特征更容易区分数据点。
准备数据:归一化数值
观察原始数据我们发现:每年飞行里程数的数量级远大于其余两个特征。在利用kNN计算样本之间的距离时,数值大的该特征会极大地影响最终的结果,也就是说,数量值大小会影响特征对结果影响的权重,而我们这里认为三个特征是同等重要的。
因而在处理这种情况时,我们通常采用的方法是将数值归一化,如将取值范围处理为0到1或者-1到1之间。下面的公式可将特征值转化为0到1区间内的值:\(newValue = \frac{oldValue - min}{max - min}\),其中 \(min\) 和 \(max\) 分别是数据集中的最小特征值和最大特征值。我们需要在脚本 kNN.py 中增加一个函数 autoNorm,自动将数字特征值转化为0到1区间内的值。
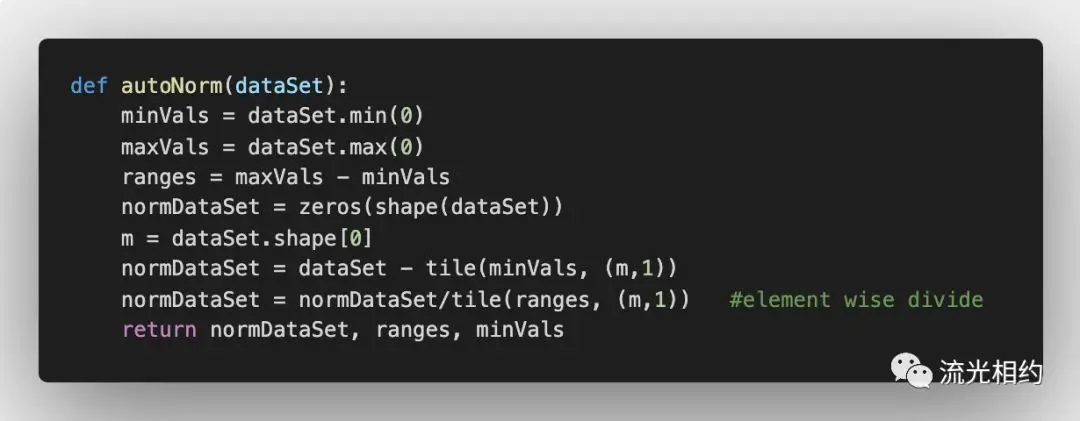
我们将每列的最小值放在变量minVals中,每列最大值放在变量maxVals中,其中的参数0使得函数可以从列中选取最小值和最大值。然后函数计算可能的取值范围,并创建新的返回矩阵。
正如前面给出的公式,为了归一化特征,我们使用当前值减去最小值,然后除以取值范围。而需要注意的是,特征值矩阵有1000*3个值,而minVals和maxVals的值都为1*3。为了解决这个问题,我们使用NumPy库中函数tile将变量内容复制成输入矩阵同等大小的矩阵,然后再利用具体特征值相除得到归一化后的特征矩阵。需要注意的是:对于某些数值处理软件包,/可能意味着矩阵除法,但在NumPy库中,矩阵除法需要使用函数linalg.solve(matA,matB)。
我们重新加载kNN.py模块,执行函数autoNorm:
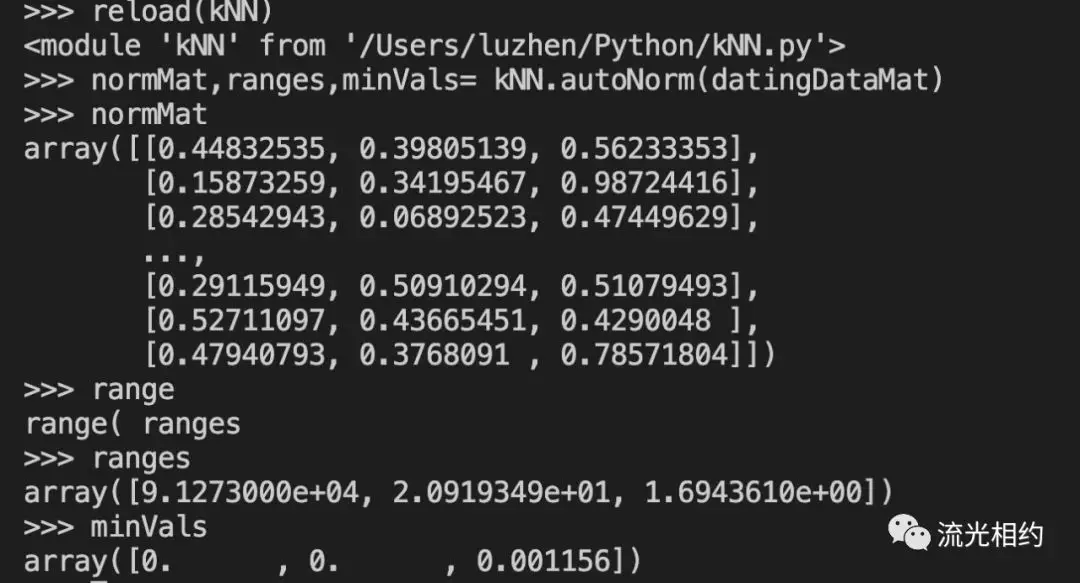
这里我们也可以只返回normMat矩阵,但是后面我们需要取值范围和最小值来归一化需要测试的新数据。
测试算法:作为完整程序验证分类器
我们已经对数据按照需求进行了处理,下面我们来测试分类器的效果。我们将已有数据的90%作为训练集来训练分类器,使用余下的10%作为测试集,检测分类器的错误率。这里由于海伦提供的数据并没有按照特定目的来排序,因而我们可随意选择10%数据而不影响测试集选择的随机性。
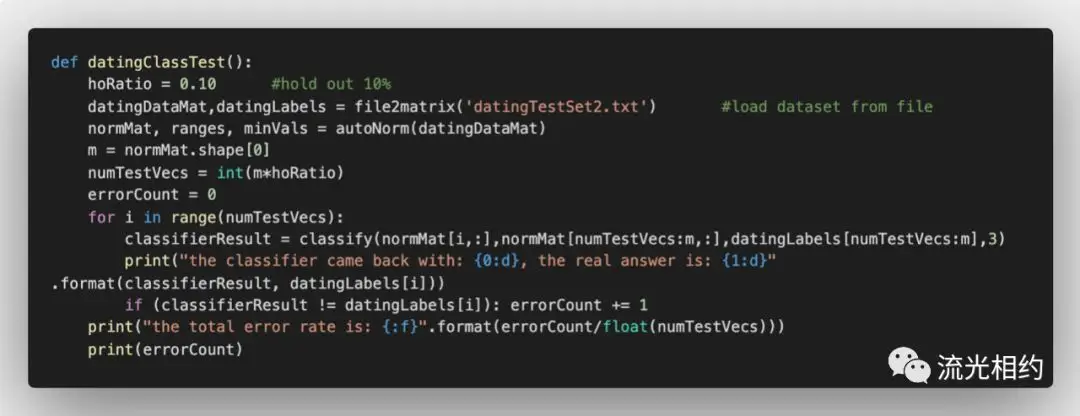
转换数据格式并归一化后,我们决定哪些数据用于测试,然后将训练集和测试集输入到kNN分类器classify函数中,计算错误率并输出分类结果。
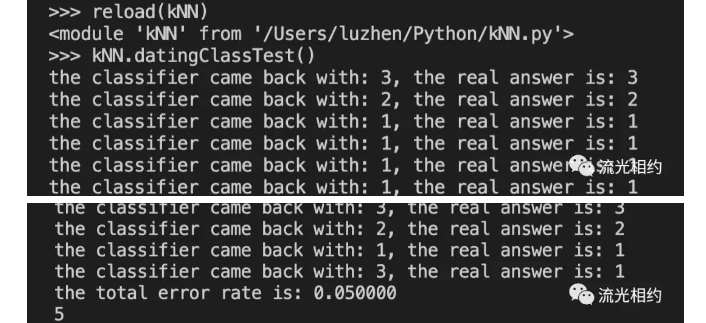
kNN分类器在测试集上的错误率为5%。我们可以改变函数datingClassTest内变量hoRatio和变量k的值,看看错误率是否会发生一些变化。
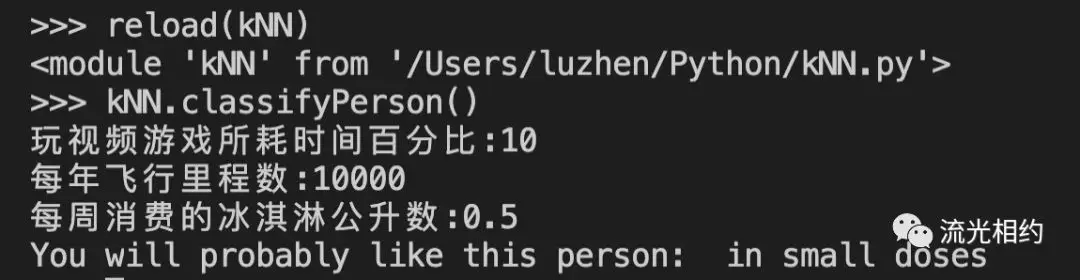
现在,海伦可以输入未知对象的特征信息,由的分类器来帮助她判定某一对象的可交往程度:讨厌、一般喜欢、非常喜欢。
使用算法:构建完整可用系统
我们会给海伦一小段程序,通过该程序海伦会在约会网站上找到某个人并输入他的信息,程序会给出她对对方喜欢程度的预测值。
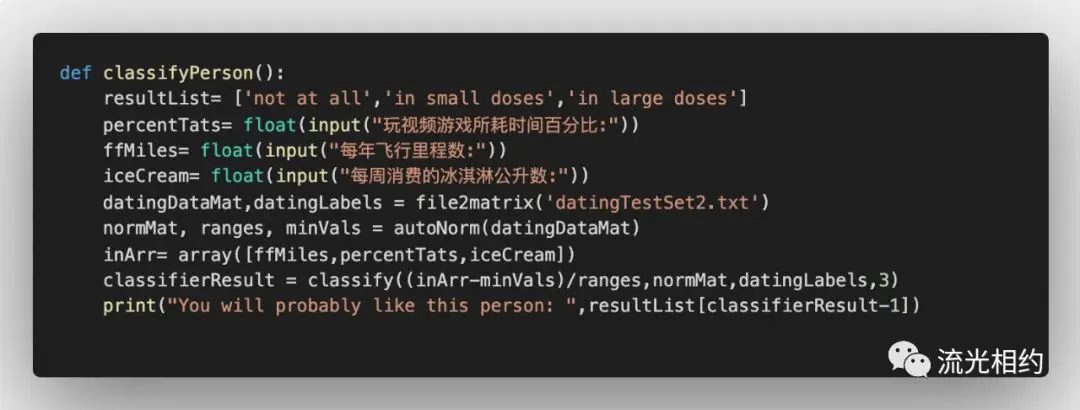
这里使用input函数获取用户控制台的输入。我们让海伦给出她在约会网站上新找的一个人信息。由于NumPy库提供的数组操作并不支持Python自带的数组类型,因此在编写代码时要注意不要使用错误的数组类型。另外在输入新样本时注意将其归一化处理。
这样,我们就完成了kNN对约会网站的配对效果的改进了。