R语言基础–因子
r
programming
R Training

因子
因子在R中非常重要,因为它决定了数据的分析方式以及如何进行结果展示。因子也在R中具有许多强大运算的基础,包括许多针对表格数据的运算。因子的设计思想来源于统计学中的名义变量或分类变量,这些变量本质上不是数字,而是对应分类。例如血型,尽管可以用数字对它们进行编码。
变量可分为名义型(无序分类变量)、有序型(表示顺序而非数量关系)和连续型变量。连续型变量可以呈现某个范围内的任意值,同时表示顺序和数量,如年龄是一个连续型变量。R中名义型变量和有序型变量称为因子。
函数factor()以一个整数向量的形式存储类别值,同时一个由字符串(原始值)组成的内部向量将映射到这些整数上,如:

将此向量存储为(1, 2, 1, 1),并在内部将其关联为1=Type1和2=Type2(具体赋值根据字母顺序决定)。针对向量diabetes进行的任何分析都会将其视为名义型变量并自动选择合适的统计方法。
在R中,因子可以简单地看作一个附加更多信息的向量(尽管它们内部机理是不同的)。这额外的信息包括向量中不同值的记录,我们称之为”水平”。
要表示有序型变量,需要为函数factor()指定参数ordered=TRUE,如:
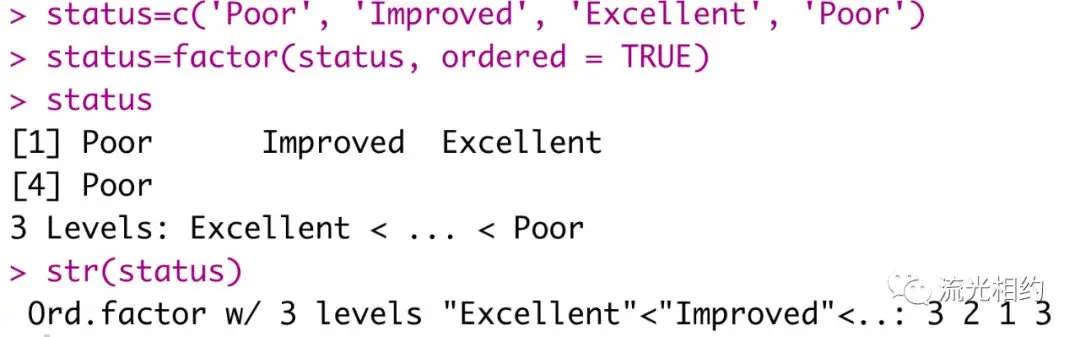
此时顺序为’Excellent’‘Improved’‘Poor’(对于字符型向量,因子的水平默认依字母顺序创建),这里恰好与逻辑顺序一致。若不一致,可以通过指定levels选项覆盖默认排序:
