星球JC | 胃癌早期筛查工具

大家好,这一期预测模型星球Journal Club的分享来自中国医科大学的徐林玉同学,分享的是2019年发表在中科院医学1区的顶级期刊Gut上,题为”Development and validation of a prediction rule for estimating gastric cancer risk in the Chinese high-risk population: a nationwide multicentre study”的研究论文。
研究背景
胃癌是中国第二常见的癌症,早期检测和治疗可以显著降低其死亡率。然而,由于高风险人群庞大,全面的胃镜筛查在经济和操作上都不切实际。当前,中国的国家筛查指南建议对高风险人群从40岁开始进行筛查,但由于高风险人群估计超过3亿人,全面的胃镜筛查并不可行。因此,迫切需要一种风险分层工具,作为胃镜检查前的初步筛查工具,以进一步识别真正的高风险个体;且当前中国国内尚无类似的工具。
现有的筛查工具主要基于已知的胃癌风险因素,如萎缩性胃炎和幽门螺杆菌感染。虽然有一些方法如ABC方法在日本被开发用于预测未来胃癌的发生,但其在中国高风险人群中的适用性仍存在疑问。此外,现有的生物标志物组合方法虽然在某些研究中表现良好,但其结果可能不适用于中国的高风险人群。因此,这项全国多中心横断面研究的目标是开发一种新的预测规则,用于二级预防(早发现、早诊断、早治疗),作为初步筛查工具,用于在中国无症状人群中识别高风险个体,以便进一步进行诊断性胃镜检查。
研究方法
研究类型
全国、多中心、横断面研究。
研究人群
年龄在40至80岁之间、无胃肠道症状的个体,符合中国胃癌高风险标准,并前往医院进行胃镜筛查。
数据收集
通过问卷调查、血清学检测(PG I、PG II、G-17、抗幽门螺杆菌IgG抗体)、胃镜检查和组织学检查收集数据。
统计分析
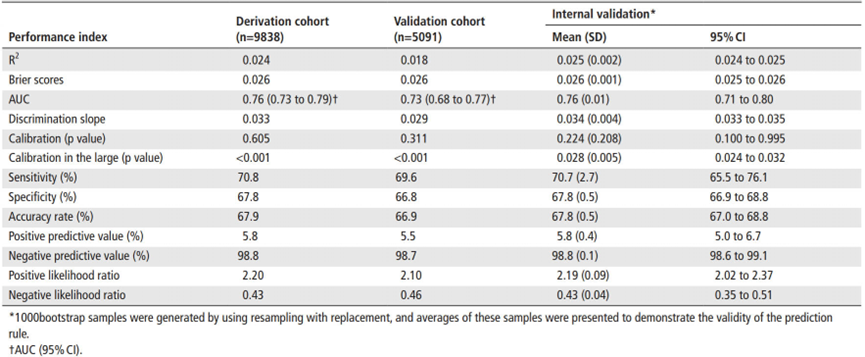
文章对数据的管理采取了中心化的管理,尽可能确保数据质量。参与者按2:1比例被随机分为开发队列和验证队列。开发队列用于模型开发,验证队列用于外部验证。文章利用Logistic回归模型开发预测规则。在开发队列中,通过univariate and multivariate analyses评估危险因素与胃癌的关联,其中,univariate analyses阈值设为p<0.25,且multivariate analyses采用backward stepwise进行进一步的变量筛选。文章预测规则的设定基于regression coefficient-based scoring method(Points were assigned by dividing the regression coefficients by the absolute value of the smallest coefficient in the model and rounding up to the nearest integer)。模型整体性能通过R²和Brier评分进行衡量,区分能力通过AUC和discrimination slope评估,校准能力通过Hosmer-Lemeshow χ2统计量和calibration in the large进行评估。同时,评估模型预测的敏感度、特异度、准确率、阳性预测值(positive predictive value)、阴性预测值(negative predictive value)、阳性似然比(positive likelihood ratio)、阴性似然比(negative likelihood rario)和number needed to screen(defined as the number of participants who would need to undergo gastroscopy for one patient with GC to be identified)。文章对开发队列进行bootstrap抽样1000次作为内部验证,验证队列上进行外部验证。同时,基于u test比较模型在开发队列、验证队列上的AUC表现。此外,文章额外做了一部分工作,即将自身模型与当前现有文献中的预测模型进行效果的对比。数据分析使用IBM SPSS和R软件进行。
研究结果
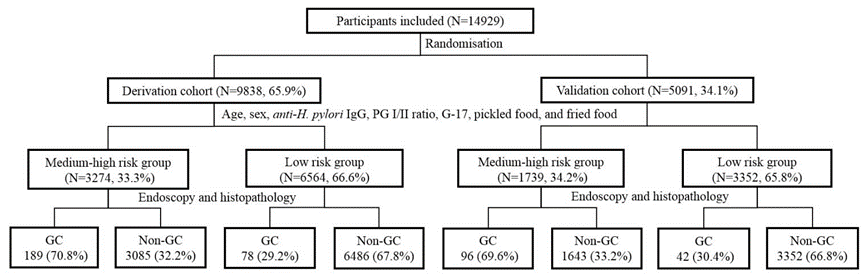
此研究收集了2015年6月至2017年3月期间来自中国115家医院的数据,最终纳入14,929名合格参与者。
预测规则的开发
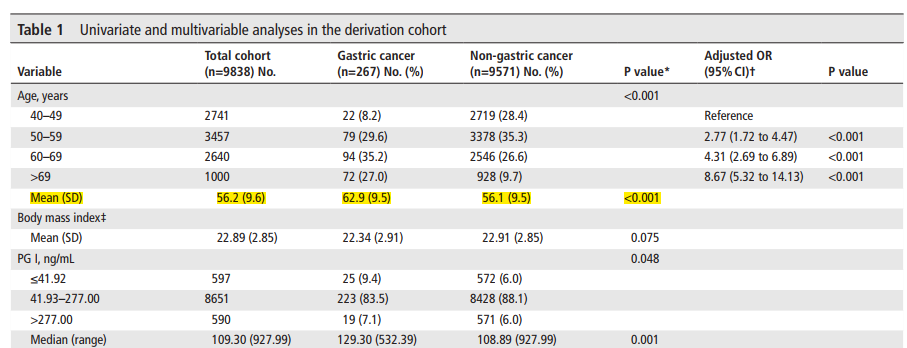
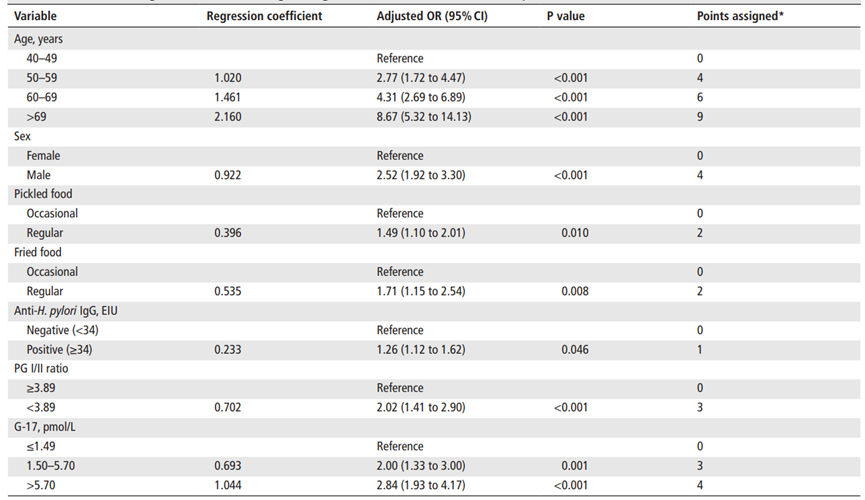
基于分数的预测规则的开发:采用单因素和多因素分析,确定了包括年龄、性别、PG I/II比率、G-17水平、幽门螺杆菌感染和饮食习惯(腌制和油炸食品消费)在内的7个预测因素。
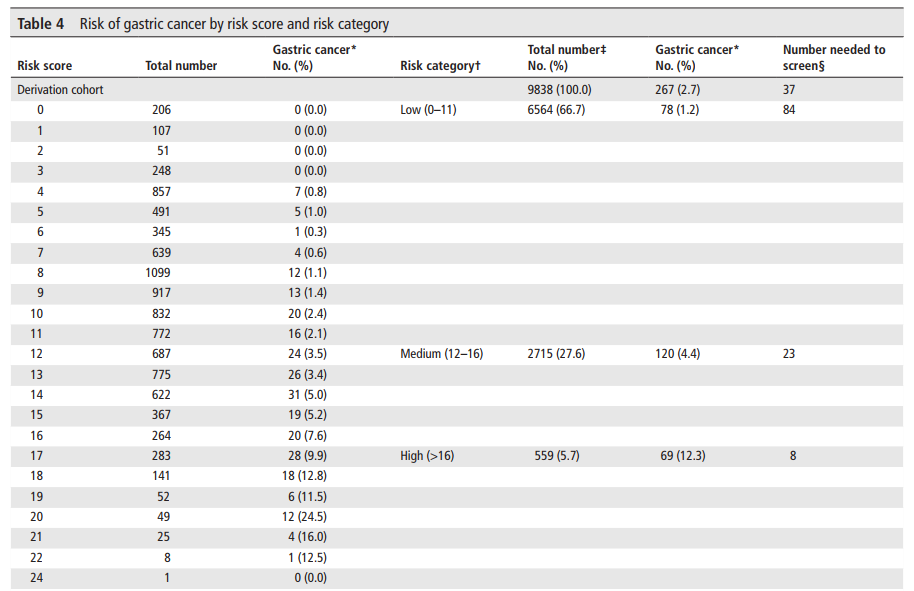
按照0–25分评分范围进行风险分层,将个体分为低风险(≤11)、中风险(12–16)和高风险(17–25)组。
其中,中高风险组的胃镜检查检测到70.8%的胃癌病例和70.3%的早期胃癌病例。低风险组的胃镜检查需求减少了66.7%。
预测性能:开发的预测规则具有良好的性能表现。
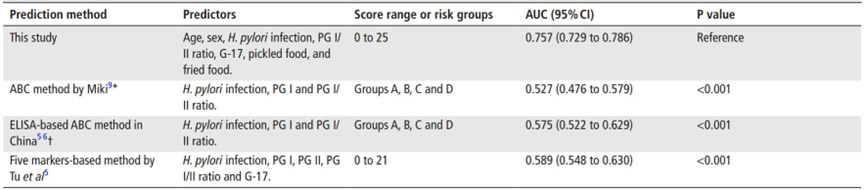
与其他预测模型的性能比较
该预测规则表现良好,并显示出显著优于其他三种替代预测方法(即Miki等人的ABC方法、中国的基于ELISA的ABC方法以及Tu等人的五种生物标志物方法)在识别胃癌患者方面的区分能力。
Take home message
该预测规则在识别中国人群中胃镜检查前的高风险个体方面表现良好。可以作为一种准确且具有成本效益的大规模初步筛查工具,以提高胃癌(包括早期胃癌)的检测率,从而改善胃癌的二级预防。
文章不仅比较了自身模型在多中心外部验证中的效果,更是对比了现有模型,且表现均优于现有模型。
采用回归赋分的方式,对于人工智能算法解释性较好,能较好地在医院中进行推广应用;此外,采用赋分划分亚组的方式,关注到了模型实际可能带来的收益。