临床试验中基线数据p值真的有意义吗?

在临床试验的结果表格中,你是否经常见到患者人口学与基线特征的统计表,附带一堆 p 值?这些 p 值到底在验证什么?是证明随机化的成功,还是暴露试验设计的漏洞?
这里,我们试图用一篇文章来讨论下这个问题。
随机化的完美幻觉:基线表格里的 p 值
临床试验的核心是随机化分配(Randomization),它试图通过不可预测的分组消除混杂因素。然而,许多论文在结果部分展示基线数据时,会针对性别、年龄等变量计算治疗组间的 p 值。这看似严谨的操作,实则暗藏争议。
我们争议的焦点在于:
1. 无意义论
如果试验已声明进行了随机化,则所有基线差异(无处理效应)的 p 值本质上反映的是随机误差,而非真实效应。任何由极小 p 值提示的统计显著性都是第一类错误,毫无意义。例如,在 100 次基线比较中,即使完全随机,按 5% 显著性水平也会出现 5 次假阳性。
2. 验真派
认为 p 值可用于验证随机化是否真实执行。比如,若基线变量显示系统性差异(如年龄显著不均衡),可能暗示分配过程存在人为干扰。
当组间均衡性遭遇挑战:何时该调整协变量?
随机化的理想情况是治疗组间基线完全均衡,但现实往往骨感。当某个预后因素(如疾病严重程度)不均衡时,该如何处理?这里,我们一般的逻辑是:
1. 不调整也能成立
即使基线不均衡,对于真正的随机化试验,我们仍然可以相信在没有纳入任何协变量的情况下,处理效应主分析的直接结果。无论观察到的处理与协变量之间的关联性如何,主效应分析的结果仍然是有效的。从这个角度看,基线表格里的 p 值是毫无必要的。
2. 调整会更高效
而另一方面,若某变量与结局强相关且组间不均衡,纳入协变量分析(如 ANCOVA 模型)可减少误差、提升统计效能。
实战指南:如何科学设计基线表格?
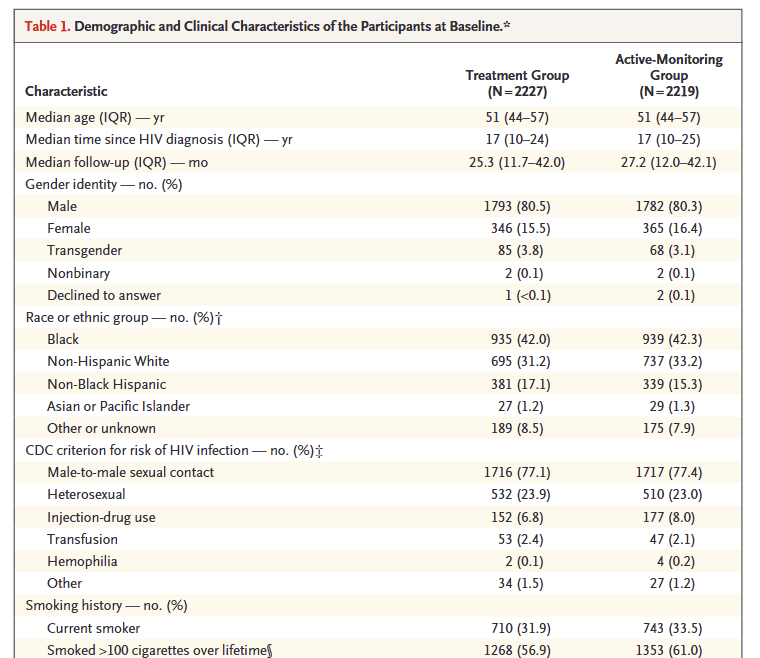
这里,我们给研究者的具体建议是:
简化p值展示:随机化试验中,基线p值无必要,直接呈现变量分布即可。
关注临床意义:若关键变量(如年龄、疾病分期)组间差异超过10%,需讨论是否调整分析模型。
结语:回归医学研究的本质
临床试验的终极目标是评估治疗效应,而非追求表格的 完美对齐。基线可比性应靠科学设计保障,而非事后修补。当一篇论文用大量 p 值自证清白时,我们或许更该追问:它的随机化是否真正无懈可击?分配过程是否足够盲态?毕竟,在医学进步的征途上,随机化需要的是技术硬核,而非统计学 p 值。