
class MultiHeaderAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super().__init__()
assert d_model % h == 0
# Assume d_v always equals d_k
self.d_k= d_model // h
self.h= h
self.linears= clones(nn.Linear(d_model, d_model), 4)
self.attn= None
self.dropout= nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
# Same mask applied to all h heads.
mask= mask.unsqueeze(1)
nbatches= query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value= [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1,2)
for lin, x in zip(self.linears, (query, key, value))
]
# 2) Apply attention on all the prokjected vectors in batch.
x, self.attn= attention(
query, key, value, mask= mask, dropout= self.dropout
)
# 3) Concat using a view and apply a final linear.
x= (
x.transpose(1,2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
del query
del key
del value
return self.linears[-1](x)手写 Transformer
transformer
nlp
deep learning
machine learning
ai
python
pytorch
Annotated Transformer
引言
Transfomer 是一种用于自然语言处理(NLP)任务的深度学习模型架构。它在2017年由 Vaswani 等人提出,并在论文《Attention is All You Need》中首次介绍。Transformer 模型的核心思想是使用自注意力机制来捕捉输入序列中不同位置之间的依赖关系,而不依赖于传统的循环神经网络(RNN)或卷积神经网络(CNN)。

这里,我们将手动搭建并实现该论文中的 Transformer 模型。我们将使用 PyTorch 框架来实现该模型,并逐步解释每个组件的功能和实现细节。
本文代码实现参考哈佛大学 The Annotated Transformer,特别致谢 Ashish Vaswani 等原论文作者。
模型架构全景
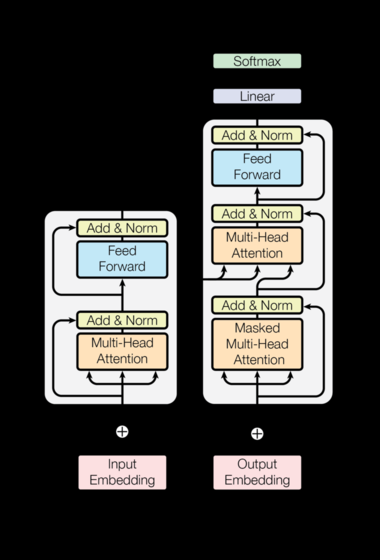
核心模块
1. 多头注意力机制(Multi-Head Attention)

注意力公式为:
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \]
代码实现:
其中,h=8 表示头数,为原文默认设置,d_model=512 表示模型的维度。
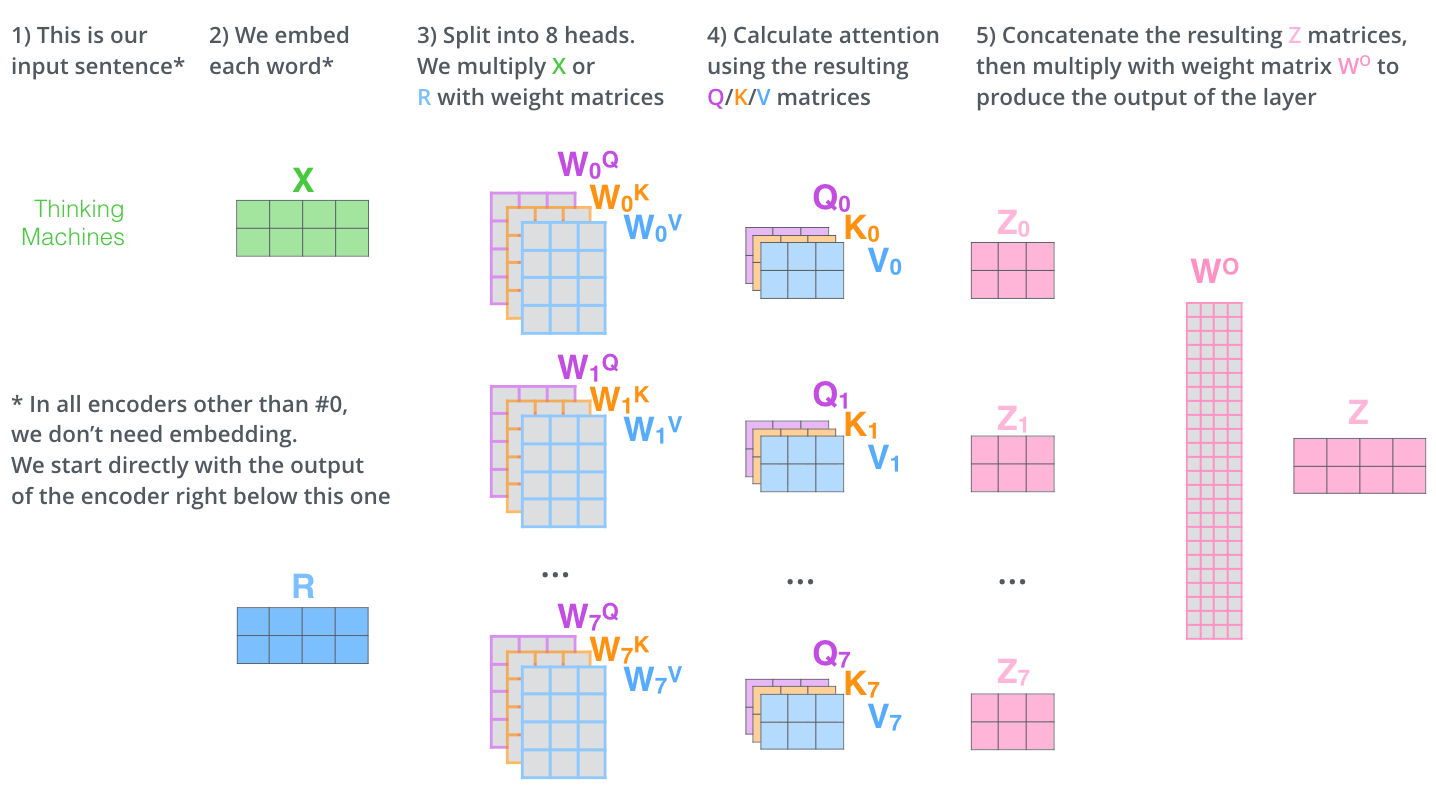
2. 位置编码(Positional Encoding)
数学公式:
\[ \text{PE}_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right) \]
\[ \text{PE}_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right) \]
代码实现:
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super().__init__()
self.dropout= nn.Dropout(p=dropout)
# Compute the positional endcodings once in log sapce.
pe= torch.zeros(max_len, d_model)
position= torch.arange(0, max_len).unsqueeze(1)
div_term= torch.exp(
torch.arange(0, d_model, 2) * -(math.log(1000.0)/d_model)
)
pe[:,0::2]= torch.sin(position * div_term)
pe[:,1::2]= torch.cos(position * div_term)
pe= pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x= x+ self.pe[:,:x.size(1)].requires_grad_(False)
return self.dropout(x)3. 编码器层(Encoder Layer)
架构组成:
自注意力子层
前馈神经网络子层
残差连接和层归一化
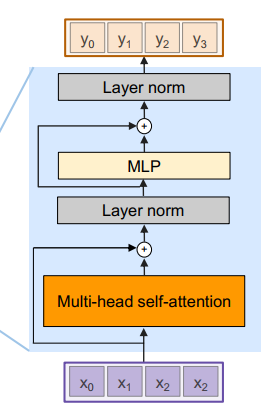
代码实现:
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward."
def __init__(self, size, self_attn, feed_forward, dropout):
super().__init__()
self.self_attn= self_attn
self.feed_forward= feed_forward
self.sublayer= clones(SublayerConnection(size, dropout), 2)
self.size= size
def forward(self, x, mask):
x= self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)4. 解码器层(Decoder Layer)
架构组成:
带掩码的自注意力子层
编码器-解码器注意力子层
前馈神经网络子层

代码实现:
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super().__init__()
self.size= size
self.self_attn= self_attn
self.src_attn= src_attn
self.feed_forward= feed_forward
self.sublayer= clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
m= memory
x= self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x= self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)其中,掩码生成函数如下:
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape= (1, size, size)
subsequent_mask= torch.triu(torch.ones(attn_shape, dtype=torch.bool), diagonal= 1)
return ~subsequent_mask借助于 subsequent_mask 函数,我们可以生成一个上三角矩阵,用于掩码掉后续位置的注意力权重。
5. 模型初始化与参数设置
def make_model(
src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1
):
"Helper: Construct a model from hyperparameters."
c= copy.deepcopy
attn= MultiHeaderAttention(h, d_model)
ff= PositionWiseFeedForward(d_model, d_ff, dropout)
position= PositionalEncoding(d_model, dropout)
model= EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab)
)
# Initiailize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model训练过程
1. 动态学习率调整
公式:
\[ \text{lr} = \text{d_model}^{-0.5} \cdot \text{min}(\text{step}^{-0.5}, \text{step} \cdot \text{warmup}^{-1.5}) \]
代码实现:
def rate(step, model_size, factor, warmup):
"""
We have to default the step to 1 for LambdaLR function to avoid zero rasing to negative power.
"""
if step == 0:
step = 1
return factor * (model_size ** -0.5) * min(step ** -0.5, step * warmup ** -1.5)学习率变化曲线:
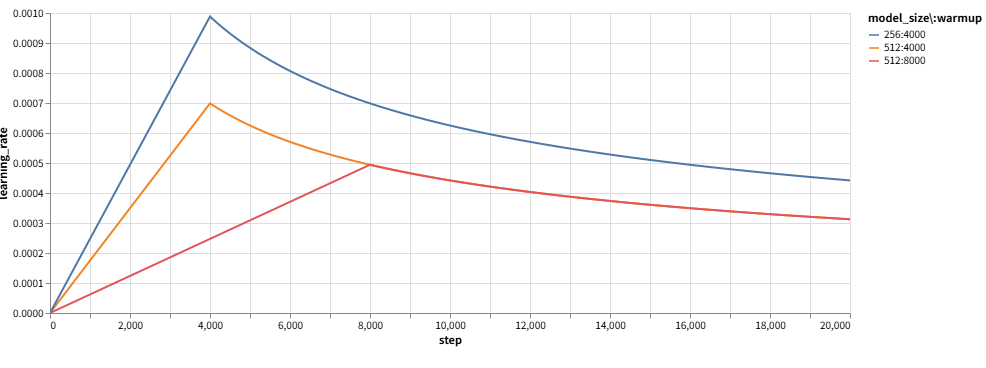
前4000步线性增长,之后指数衰减。
2. 标签平滑(Label Smoothing)
标签平滑是一种正则化技术,用于缓解模型过拟合和提高泛化能力。它通过将目标标签的概率分布进行平滑处理,使得模型在训练时不会过于自信地预测某个特定的标签。
代码实现:
class LabelSmoothing(nn.Module):
"""
Implement label smoothing.
"""
def __init__(self, size, padding_idx, smoothing=0.0):
super().__init__()
self.criterion= nn.KLDivLoss(reduction='sum')
self.padding_idx= padding_idx
self.confidence= 1.0 - smoothing
self.smoothing= smoothing
self.size= size
self.true_dist= None
def forward(self, x, target):
assert x.size(1) == self.size # vocab_size
true_dist= x.data.clone() # clone the data to avoid in-place operation
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx]= 0 # ignore the category of padding_idx
mask= torch.nonzero(target == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist= true_dist
return self.criterion(x, true_dist.clone().detach())3. 分布式训练加速
多 GPU 训练:
def train_worker(
gpu,
ngpus_per_node,
vocab_src,
vocab_tgt,
spacy_de,
spacy_en,
config,
is_distributed= True
):
print(f'Train worker process using GPU: {gpu} for training', flush=True)
torch.cuda.set_device(gpu)
pad_idx= vocab_tgt["<blank>"]
d_model= 512
model= make_model(len(vocab_src), len(vocab_tgt), N=6)
model.cuda(gpu)
module= model
is_main_process= True
if is_distributed:
dist.init_process_group(
backend='nccl',
init_method='env://',
rank=gpu,
world_size=ngpus_per_node
)
model= DDP(model, device_ids=[gpu])
module= model.module
is_main_process= gpu == 0
criterion= LabelSmoothing(
size=len(vocab_tgt),
padding_idx=pad_idx,
smoothing=0.1
)
criterion.cuda(gpu)
train_dataloader, valid_dataloader= create_dataloaders(
gpu,
vocab_src,
vocab_tgt,
spacy_de,
spacy_en,
batch_size=config['batch_size'] // ngpus_per_node,
max_padding=config['max_padding'],
is_distributed=is_distributed
)
optimizer= torch.optim.Adam(
model.parameters(),
lr=config['base_lr'],
betas=(0.9, 0.98),
eps=1e-9
)
lr_scheduler= LambdaLR(
optimizer= optimizer,
lr_lambda= lambda step: rate(
step, model_size=d_model,
factor=1, warmup=config['warmup']
)
)
train_state= TrainState()
for epoch in range(config['num_epochs']):
if is_distributed:
train_dataloader.sampler.set_epoch(epoch)
valid_dataloader.sampler.set_epoch(epoch)
model.train()
print(f'[GPU {gpu}] Epoch {epoch} Training ====', flush=True)
_, train_state= run_epoch(
(Batch(b[0], b[1], pad_idx) for b in train_dataloader),
model,
SimpleLossCompute(module.generator, criterion),
optimizer,
lr_scheduler,
mode='train+log',
accum_iter=config['accum_iter'],
train_state=train_state
)
GPUtil.showUtilization()
if is_main_process:
file_path= '%s%.2d.pt' % (config['file_prefix'], epoch)
torch.save(module.state_dict(), file_path)
torch.cuda.empty_cache()
print(f'[GPU {gpu}] Epoch {epoch} Validation ====', flush=True)
model.eval()
sloss= run_epoch(
(Batch(b[0], b[1], pad_idx) for b in valid_dataloader),
model,
SimpleLossCompute(module.generator, criterion),
DummyOptimizer,
DummyScheduler,
mode='eval'
)[0]
print(f'[GPU {gpu}] Epoch {epoch} Validation Loss: {sloss}', flush=True)
torch.cuda.empty_cache()
if is_main_process:
file_path= '%sfinal.pt' % (config['file_prefix'])
print(f'Training finished.\nModel saved to {file_path}.pt.', flush=True)
torch.save(
module.state_dict(),
file_path
)实例
我们使用 WMT 2014 英德翻译数据集进行训练,完成德语到英语的翻译任务。
完整注释的 python 代码已经放进了星球里。