生统爱好者周刊(第 18 期):一些大学老师开始坐班了

这里记录每周值得分享的生统相关内容,周五发布。
本杂志开源(GitHub: openbiostat/biostat-weekly),欢迎提交 issue 投稿或推荐生统相关内容。
封面图

本周话题:一些大学老师开始坐班了
近年来部分高校逐步推行的教师坐班制,在编制收紧、行政人力不足与绩效考核压力并存的背景下,部分民办高校、专科院校及”双非”高校要求新入职教师在承担教学与科研任务的同时,长期参与行政坐班工作,形成了”教学—科研—行政”高度叠加的工作模式。
生统研究
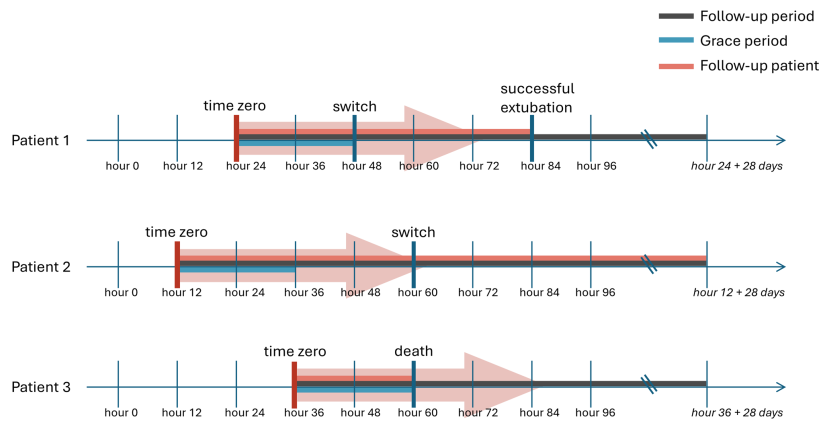
系统综述了目标试验模拟(Target Trial Emulation, TTE)在重症医学临床研究中的应用潜力、方法学挑战及未来发展方向。文章指出,在重症医学领域,由于随机对照试验(RCT)在伦理、可行性和成本方面常受限制,基于真实世界数据(如ICU电子病历和多中心数据库)开展因果推断研究已成为重要补充,而TTE为此提供了一个以因果推断为核心的系统化研究框架。作者强调,TTE通过明确”理想随机试验”的关键要素(研究对象、治疗策略、随访起点、结局定义及因果对比方式),有助于减少观察性研究中常见的偏倚,如不朽时间偏倚和选择偏倚。与此同时,文章也深入讨论了在重症医学场景下实施TTE所面临的挑战,包括治疗时序高度动态化、时间依赖性混杂、结局与暴露定义复杂以及数据质量异质性等问题。最后,作者展望了TTE在结合因果图、先进统计方法和机器学习技术方面的发展前景,认为其有望成为提升重症医学真实世界证据质量、推动临床决策优化的重要方法学工具。
- 论文 DOI:10.1186/s13054-025-05723-x
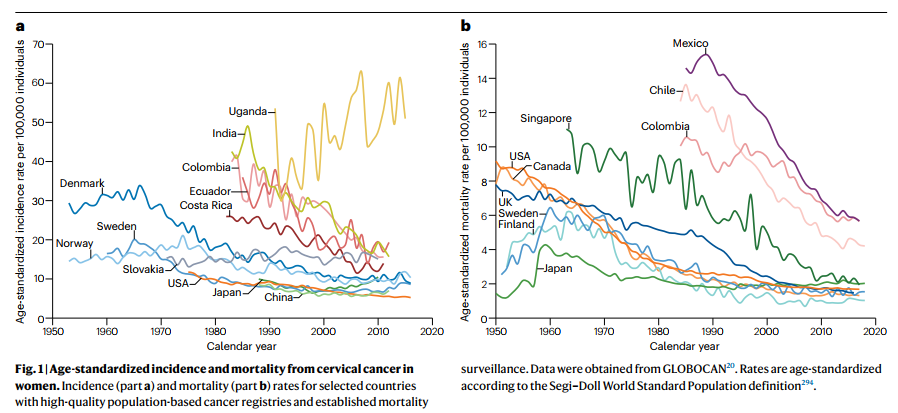
宫颈癌是第一个被认为可以通过预防来消除的癌症,因此从这种癌症类型的流行病学和预防中获得的经验可以为管理其他癌症提供策略信息。人类乳头瘤病毒(HPV)感染几乎会导致所有的宫颈癌,以及相当比例的口咽、肛门和生殖器癌症。虽然20世纪的预防工作主要由细胞学筛查主导,但HPV相关癌症预防的现在和未来主要依赖于HPV疫苗接种和分子筛查测试。在这篇综述中,作者提供了HPV相关癌症流行病学的概述,它们的疾病负担,以及过去和当代预防干预措施如何塑造了它们的发病率和死亡率,以及消除的潜力。作者特别关注可能对预防工作产生最大影响的共因素,如生育次数和人类免疫缺陷病毒感染,以及健康社会决定因素。鉴于HPV相关癌症的发病率和死亡率仍然与个人的社会经济地位和国家的人类发展指数密切相关,除非预防工作专注于健康公平,并致力于初级和二级预防,否则消除工作不太可能成功。
- 论文 DOI:10.1038/s41571-024-00904-z
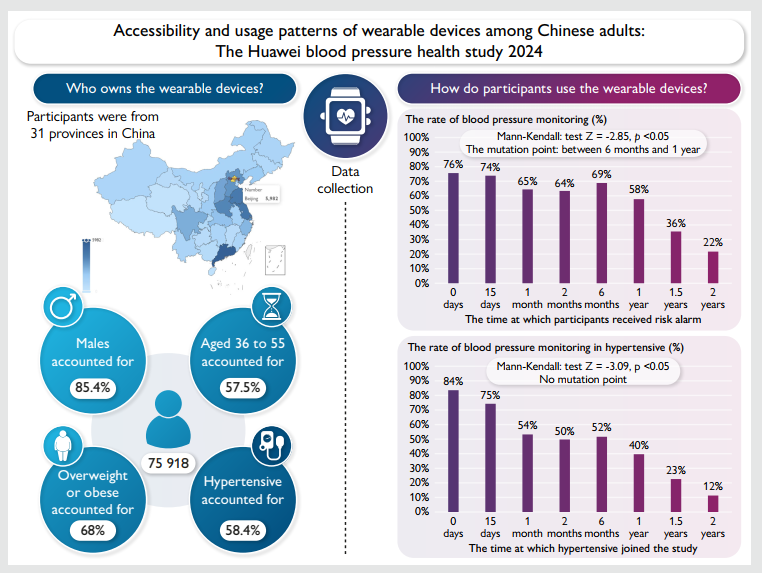
这一项大规模真实世界研究首次系统揭示了中国成年人中可穿戴健康设备的拥有情况与使用模式,为高血压管理的数字化创新提供了关键实证依据。本研究首次在大规模真实世界场景中,系统描绘了中国可穿戴设备在血压管理中的应用现状,主要结论如下:存在显著的数字健康鸿沟:可穿戴设备的获取和使用在中国人群中存在明显的人口学与地域差异。设备健康功能利用严重不足:睡眠和运动监测等高级功能的开启率低,血压监测的长期依从性有待提高。提出优化随访间隔建议:基于依从性下降模式,研究为基于可穿戴设备的高血压管理提出了潜在的优化随访间隔建议:对于收到风险警报的高危人群,建议每年进行一次随访督促;对于已确诊的高血压患者,建议每半年进行一次随访,以维持其血压监测依从性。
- 论文 DOI:10.1093/ehjdh/ztaf088
博文资讯

围绕倾向性评分分析(Propensity Score Analysis, PSA)中的关键起点——倾向性评分模型的协变量选择展开,强调变量选择并非”越多越好”,而是一项以因果推断理论为纲、以领域知识为主、以数据驱动为辅、以平衡诊断为最终裁决的系统工作。
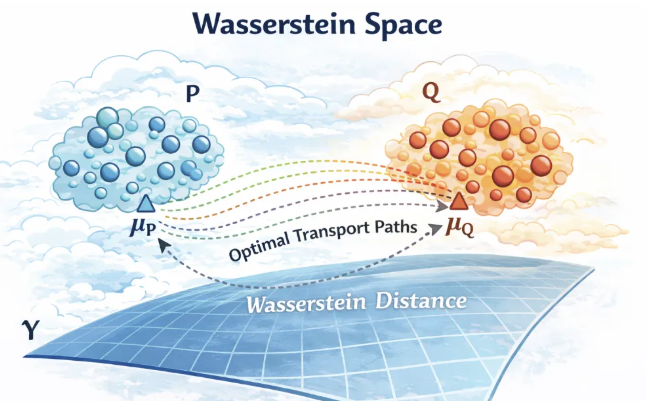
文章立足于最优传输理论与非欧几里得统计框架,将概率分布视为 Wasserstein 空间中的几何对象,针对传统回归模型无法直接处理”分布作为变量”的局限,提出在 Fréchet 均值处对分布空间进行线性化,并在切丛(tangent bundle)中构建函数型回归模型,从而实现分布—分布之间的回归建模与预测。
- 论文 DOI:10.1080/01621459.2021.1956937

Jacob Bernoulli(雅各布·伯努利,1655–1705) 是瑞士数学家,概率论的奠基者之一,也是著名的伯努利家族中最早产生深远影响的学者。他对概率、组合数学、无穷级数以及后来的统计思想产生了决定性影响。伯努利首次严格证明了大数定律:当试验次数足够大时,随机事件的频率会稳定地趋近其真实概率。伯努利最重要的并非某一个公式,而是一种认知转变,而这正式后来统计学、概率模型、随机过程、现代机器学习不确定建模的思想源头。
工具

ggdag 是一个用于绘制和分析有向无环图(Directed Acyclic Graph, DAG)的 R 包,主要服务于因果推断和流行病学研究。该包结合 dagitty 的因果建模能力与 ggplot2 的可视化框架,可用于构建、展示和解释变量之间的假定因果关系结构。ggdag 支持识别混杂因素、调整变量集以及可视化因果路径,在研究设计、变量选择和因果假设说明中具有重要作用,广泛应用于观察性研究和因果推断分析中。
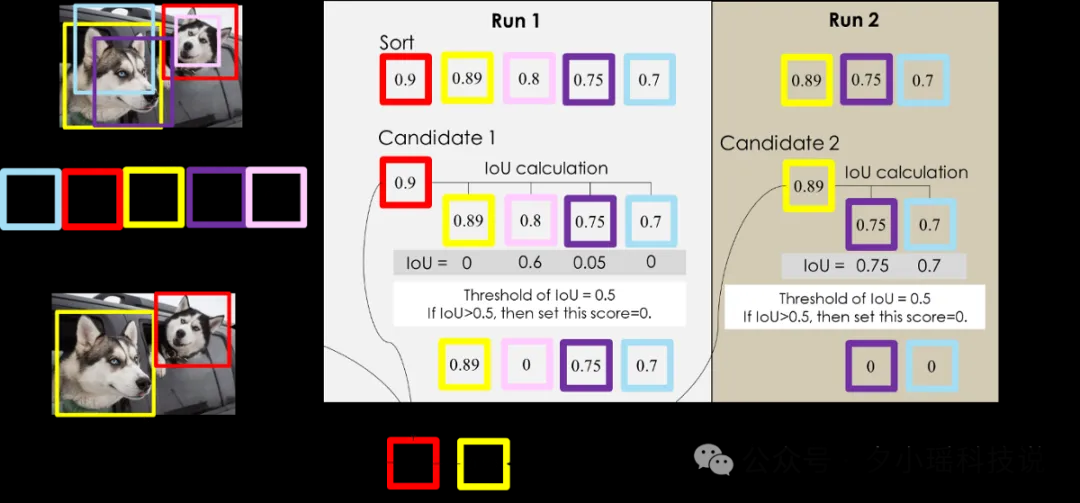
YOLO 的版本号,直接从 11 跳到了 26。与 YOLO11 相比,YOLO26 的 Nano 版本在 CPU 推理场景下最高可实现 43% 的性能提升,成为目前边缘端和基于 CPU 部署场景中速度与精度兼顾的领先目标检测模型之一。这两年大模型太火了,火到很多人忘了一个基本事实——99% 的 AI 应用场景,根本用不起大模型。

Quarto 是下一代开源科学和技术出版系统,由 Posit (前 RStudio) 开发,被视为 R Markdown 的继任者。它旨在让创建和协作编写数据驱动的文档变得更加高效和统一,特别适合混合使用多种编程语言的数据科学团队。
资源

《Interpretable Machine Learning》 是 Christoph Molnar 撰写的一本系统性介绍机器学习可解释方法的开放获取著作,聚焦于在复杂模型背景下理解和解释预测结果的问题。该书从可解释性的基本概念出发,系统阐述了模型无关与模型特异的解释方法,涵盖特征重要性、部分依赖图(Partial Dependence Plot)、个体条件期望(ICE)、SHAP 值、LIME 等常用技术,并结合实际案例说明其原理、应用场景与局限性。该书强调可解释性在医学、公共卫生等高风险决策领域中的重要性,为在保证预测性能的同时提升模型透明度与临床可解释性提供了理论与实践指导。
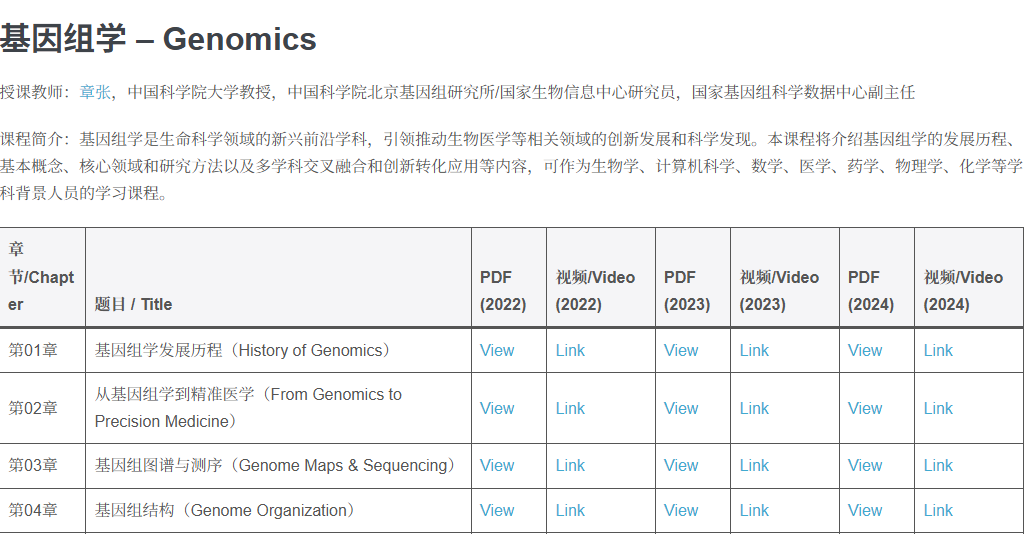
国家基因组科学数据中心(NGDC)基因组学教育平台 是由中国科学院北京基因组研究所(国家生物信息中心,CNCB-NGDC)建设的在线教学与科普平台,旨在系统化传播基因组学与生物信息学相关理论、方法与实践技能。该平台围绕基因组学基础、生物信息学分析流程、多组学数据解析等主题,整合课程讲解、案例分析与实践资源,覆盖从入门到进阶的多层次学习需求。该平台为科研人员和研究生提供了规范化、权威性的学习资源,有助于提升对高通量测序数据、生物信息学方法及基因组数据资源的理解与应用能力。
贡献者(GitHub ID)
「OpenBioStat 生统爱好者周刊」运维小组:
- [
@Leslie-Lu](陆震) - [
@YihanChen325](陈奕含) - [
@kirihsia](夏鑫辛) - [
@GCRPM](徐林玉)
订阅
本周刊每周五发布,更新在微信公众号「陆震生物统计」(luzhen-biostat)上,微信搜索陆震生物统计或者扫描二维码,即可订阅。

同时,本周刊同步支持 RSS 订阅;本周刊同名中文播客现已正式在苹果播客(Apple Podcasts)和小宇宙平台上线,搜索生统爱好者周刊即可订阅收听。该播客内容基于本周刊公开内容制作,相关学术论文链接及原始资讯请查阅本周刊文字版。
(完)