生统爱好者周刊(第 20 期):预测模型,发表即终点?

这里记录每周值得分享的生统相关内容,周五发布。
本杂志开源(GitHub: openbiostat/biostat-weekly),欢迎提交 issue 投稿或推荐生统相关内容。
封面图

本周话题:预测模型,发表即终点?
npj Precision Oncology 发表了一篇观点文章,标题犀利得让人窒息:“All models are wrong and yours are useless”(所有模型都是错的,而你的模型是无用的)。
作者 Florian Markowetz 是剑桥大学的计算生物学家,他以自己的亲身经历开刀:他参与定义的结直肠癌、乳腺癌、胰腺癌分子分型,论文发了一堆,引用量漂亮,但——没有一个在临床上被常规使用。这不是个例。一项系统综述统计了 408 个 慢性阻塞性肺病的预测模型,结论是什么?“方法学缺陷普遍,外部验证率极低。”
生统研究
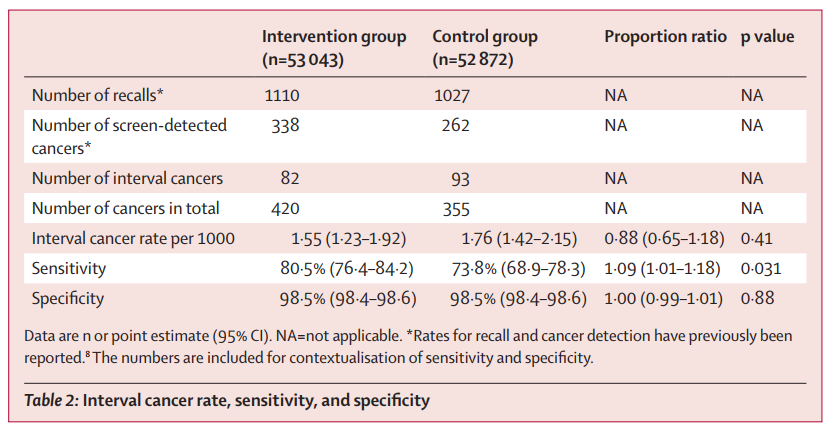
《柳叶刀》(The Lancet)最新发表全球首项探索AI用于乳腺癌筛查的10万级随机试验的完整入组结果。研究表明,AI辅助乳腺钼靶X线摄影筛查,能在乳腺癌筛查中识别更多癌症,并将随后2年内的间期乳腺癌诊断率降低12%。这为在乳腺钼靶X线摄影筛查项目中应用AI技术提供了依据。
- 论文 DOI:10.1016/S0140-6736(25)02464-X
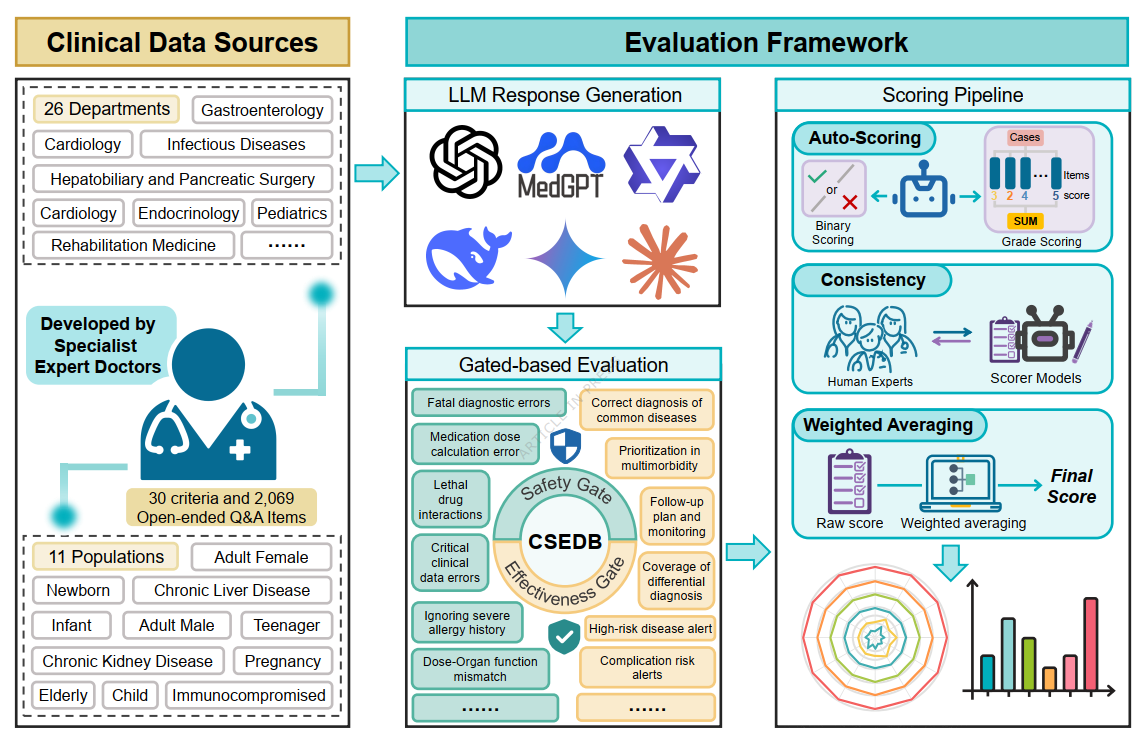
CSEDB全称为Clinical Safety-Effectiveness Dual-Track Benchmark(临床安全性与有效性双轨基准),它首次为评估医疗AI真实临床能力建立了一个基于临床专家共识、覆盖全面风险维度,并将安全性与有效性分开考量的标准化基准。通过公开实验,CSEDB直接给出了不同模型在同一标尺下的临床能力对照结果。
- 论文 DOI:10.1038/s41746-025-02277-8
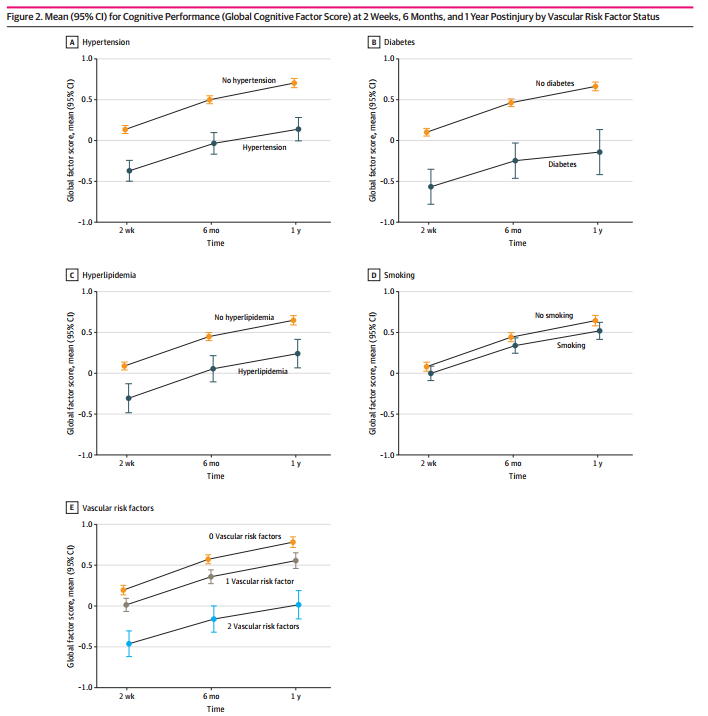
该研究采用逆概率失访加权的广义估计方程(IPAW-GEE)分析纵向认知数据,以同时评估血管危险因素与伤后早期认知水平及随访期间认知变化之间的关联。通过在模型中引入血管危险因素与时间的交互项,并将时间作为分类变量建模,研究得以刻画TBI后不同阶段认知变化的潜在非线性特征。同时为减少失访偏倚,基于多变量逻辑回归构建逆概率权重,并通过敏感性分析验证结果稳健性。
- 论文 DOI:10.1001/jamanetworkopen.2025.25719
博文资讯
2026年春季,一本叫《Vita》的国产顶刊即将上线,施一公、李党生坐镇主编,最关键的是——永久不收版面费。主编阵容堪称豪华:李党生(前《Cell Research》主编,被誉为”中国期刊第一人”)、施一公(西湖大学校长,结构生物学巨擘)。《Vita》的定位也很清晰:立足中国,面向全球,做生命科学与生物医学领域的国际级高水平平台。官网已经上线,投稿系统”浪淘沙”预印本平台同步推出,想快就用预印本,想精就投期刊,两条路都给你打通。
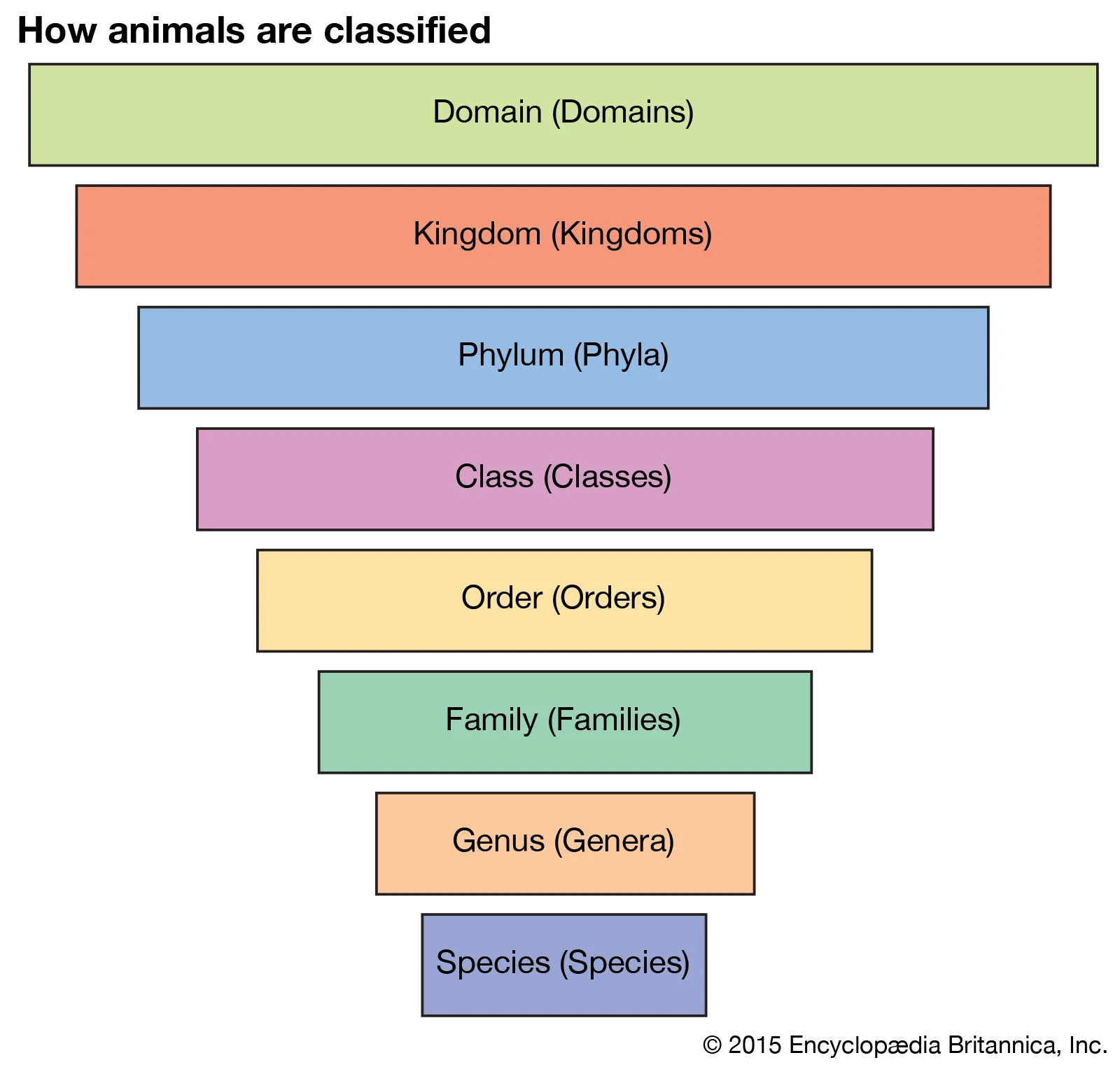
Carl Linnaeus(卡尔·林奈,1707–1778)是瑞典博物学家、植物学家和医生,被公认为现代生物分类学之父。他最重要的贡献是建立了一套统一、系统的生物命名与分类体系,至今仍是生物学研究的基础。虽然林奈不是现代意义上的医生科学家,但他的分类思想奠定了病原体分类、命名和交流的基础,为后来微生物学、传染病学中的标准化命名提供了范式,直接影响了后来进化生物学与系统发生学的发展。
工具

专为大数据集设计,在读取(fread)、写入(fwrite)、分组聚合和连接操作上速度极快,远超传统方法;支持引用语义 (Reference Semantics),即可以直接在原数据上修改(如 := 操作符),无需复制数据,从而极大节省内存。如果你在 R 中处理 GB 级别的大数据,或者追求代码的运行速度和内存效率,data.table 是不二之选。
LocusZoom Standalone 是一个用于 GWAS 区域关联结果可视化的命令行工具,由 University of Michigan School of Public Health 的研究团队开发和维护。它的核心目标是:把某一个基因组区域内的 GWAS 统计结果、连锁不平衡(LD)和基因注释,整合成一张”一眼就能读懂”的区域关联图。网页介绍了安装流程。

Homebrew 是 macOS 和 Linux 上最受欢迎的包管理器之一,它通过命令行让软件安装、升级、卸载和管理变得极为简单。Homebrew 的理念是”把开发者需要的工具和应用打包管理,免去手动下载和配置的麻烦”。Homebrew 的核心目标是让开发者在 macOS 或 Linux 上 像在 Linux 包管理器(apt/yum/pacman)中一样管理软件,保持系统整洁,同时极大提高开发效率。
资源
BioASQ 是一个面向生物医学领域的国际性评测平台与竞赛项目,核心目标是推动生物医学语义理解、信息检索与自动问答(Biomedical Question Answering, BioQA)技术的发展。它长期为学术界和工业界提供高质量数据集、统一评测标准和年度竞赛。BioASQ 的数据具有几个显著特点:基于真实 PubMed / 生物医学数据库;专家人工标注的 gold standard;多年滚动更新,支持纵向比较;非常适合:生物医学 NLP、大语言模型(LLM)评测以及RAG(检索增强生成)系统验证。

本书全面介绍了 tidymodels 框架,这是 R 语言中继 caret 之后的新一代建模系统。它展示了如何运用 “tidy”(整洁)的原则来进行建模和机器学习,由 RStudio (现 Posit) 的 Max Kuhn(caret 包和 tidymodels 的核心开发者)与 Julia Silge(知名数据科学家)合著。
贡献者(GitHub ID)
「OpenBioStat 生统爱好者周刊」运维小组:
- [
@Leslie-Lu](陆震) - [
@YihanChen325](陈奕含) - [
@kirihsia](夏鑫辛) - [
@GCRPM](徐林玉)
订阅
本周刊每周五发布,更新在微信公众号「陆震生物统计」(luzhen-biostat)上,微信搜索陆震生物统计或者扫描二维码,即可订阅。

同时,本周刊同步支持 RSS 订阅;本周刊同名中文播客现已正式在苹果播客(Apple Podcasts)和小宇宙平台上线,搜索生统爱好者周刊即可订阅收听。该播客内容基于本周刊公开内容制作,相关学术论文链接及原始资讯请查阅本周刊文字版。
(完)