生统爱好者周刊(第 27 期):AI正在改变科学发现方式?

这里记录每周值得分享的生统相关内容,周五发布。
本杂志开源(GitHub: openbiostat/biostat-weekly),欢迎提交 issue 投稿或推荐生统相关内容。
封面图

本周话题:AI正在改变科学发现方式?
如果让科学家回顾过去十年的科研变化,人工智能(AI)一定是最重要的变量之一。从蛋白质结构预测到新药发现,从材料设计到核聚变控制,AI正在逐渐进入科学研究的核心环节。AI正在从传统的科研辅助工具,逐渐演变为推动科学发现的重要基础设施。在数据处理、假说生成、实验设计以及科学模拟等多个环节,AI都开始展现出前所未有的能力。但与此同时,AI在科学领域的大规模应用,也面临着数据、算法和科研生态等多方面挑战。或许在不久的将来,一些重大科学发现的背后,都将出现人工智能的身影。
生统研究
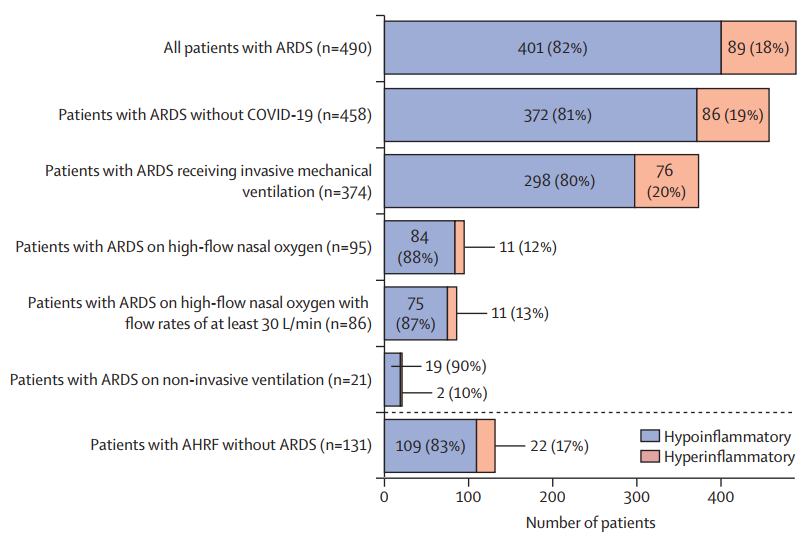
PHIND研究是一项多中心前瞻性队列研究,首次实现了急性呼吸窘迫综合征(ARDS)炎症亚表型的床旁实时识别。研究纳入512例急性呼吸衰竭患者,利用IL-6、TNFR1及碳酸氢盐水平构建简化模型,在约1小时内完成高炎症型与低炎症型分型。结果显示,高炎症亚表型占18%,其60天死亡率显著高于低炎症型(51% vs 28%,OR=2.7),且机械通气时间、ICU住院时间均显著延长。值得注意的是,两亚型在传统氧合指标上无显著差异,提示生物学分型优于单纯临床指标。本研究证实炎症亚表型具有重要预后价值,并为ARDS精准医学和分层治疗策略提供了关键技术基础。
- 论文 DOI:10.1016/S2213-2600(26)00040-8
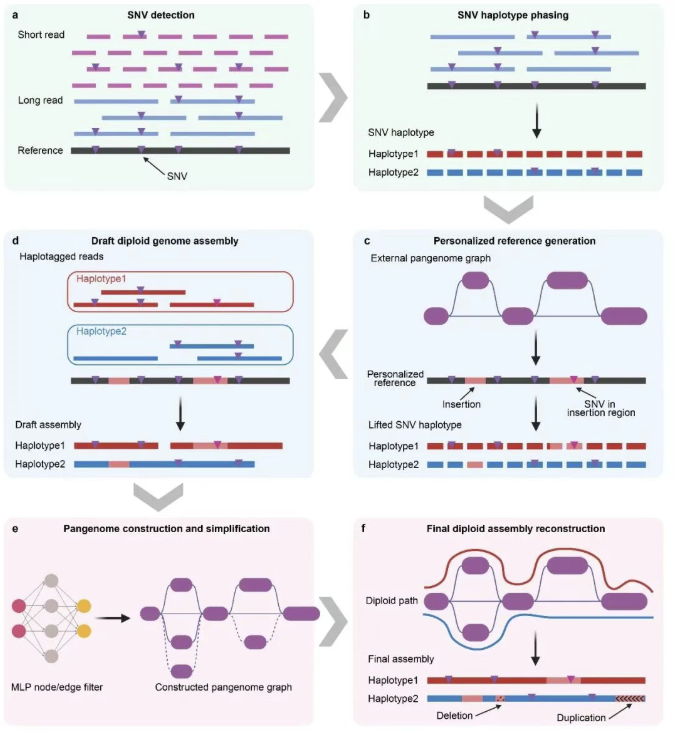
北京时间4月1日晚23时,西湖大学振星教授杨剑团队与合作者在Nature上发表最新研究成果。他们创新性地开发了基于泛基因组的联合组装(PIGA)方法,成功构建了千人泛基因组,极大突破了既往泛基因组样本量的上限。
“这项研究极大地深化了我们对复杂遗传变异及其功能的认知,彰显了基于大规模基因组组装的分析方法在填补传统测序研究空白方面的巨大潜力,为人类健康研究和其他物种泛基因组研究提供了新范式。”杨剑说。或许,在不久的将来,这套组装基因组的新方法,也将成为科学家们破解人类疾病密码、实现精准医疗的关键利器。
博文资讯

2026年3月18日,美国FDA发布了一份具有里程碑意义的草案指南,正式为替代动物实验的新方法(NAM)打开监管大门。这意味着,类器官、器官芯片、计算机模拟等前沿技术,将有望取代传统动物实验,成为药物研发的主流路径。
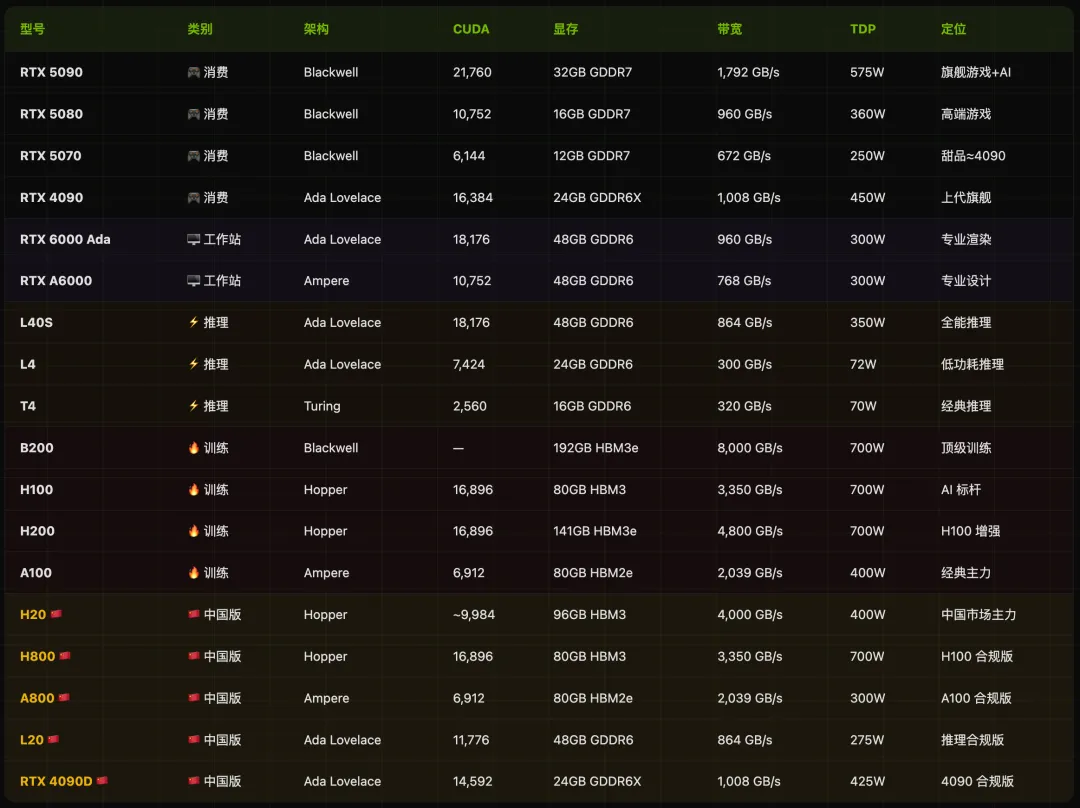
这篇文章是一份英伟达 GPU 全系列的硬核科普手册:从游戏显卡到 AI 超级芯片,覆盖消费级 GeForce(RTX 5090 ~ RTX 3090)、工作站 RTX Pro(RTX 6000 Ada / RTX A6000)、推理卡 L/T 系列(L40S / L4 / T4)、训练卡 B/H/A 系列(B200 / H200 / H100 / A100)以及中国特供版(H20 / L20 / RTX 4090D)五大产品线。
工具

微信 3 月开放了 iLink 协议(ClawBot 插件),第一次官方允许用程序收发个人号消息。OpeniLink Hub 基于这个协议做了一个开源消息管理平台:接入 AI 大模型: 填个 API Key,微信自动调 Claude、ChatGPT、Ollama 等大模型回复,微信号变 AI 助手。一行命令安装,内置 SQLite 零配置,7 种语言 SDK,MIT 开源。
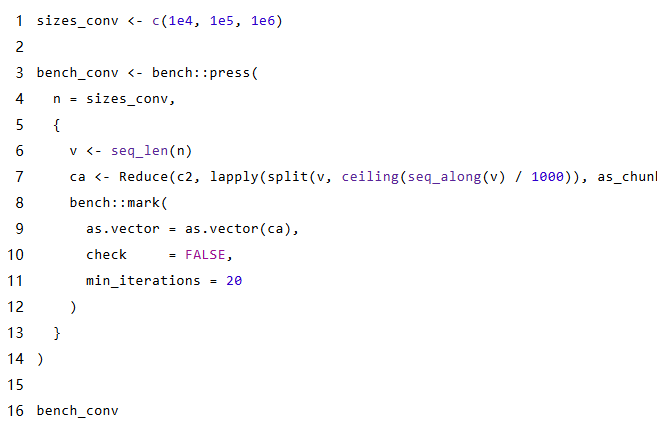
做 R 的性能优化,有一个场景几乎人人踩过坑:在循环里不断 c(v, new) 追加数据。小数据时看不出来,一旦规模上来,速度像被抽走一样。这篇文章想把话说清楚:yulab.utils 里的 chunked_array 不是”更快的向量”,它其实换了一套数据组织方式。它在”写入/拼接”上赢得很干脆,但在”随机访问”上要付成本。
资源

介绍了如何将AI深度融入个人笔记工作流。其核心为指导用户通过名为”Claudian”的插件,将Claude Code的能力整合到Obsidian笔记软件中。该方案旨在解决用户频繁在笔记工具与AI聊天窗口之间切换的痛点,使AI从一个单纯的对话伙伴,转变为拥有”读写”权限的智能协作者。安装过程的关键在于先通过”BRAT”插件加载测试版本,再进行配置。成功集成后,AI可直接读取当前笔记内容、编辑文件甚至运行代码,在知识管理、内容创作和代码调试等场景中实现一站式闭环操作,极大提升了效率与流畅度。

在数据科学项目中,类别不平衡是常见挑战,会导致模型预测严重偏向多数类。本文系统总结了五种核心应对策略。最基础的是随机欠采样和过采样,通过增减样本来平衡数据分布。更优的方法是SMOTE,它为少数类合成新样本。另一种高级策略是集成学习(如XGBoost),其算法机制天然有助于关注少数类。而最被推荐、最简便高效的方法是调整类别权重,它无需修改数据,只需在模型训练时(如设置class_weight=‘balanced’)为少数类分配更高的损失权重,即可引导模型平等学习所有类别,是实践中优先考虑的首选方案。
贡献者(GitHub ID)
「OpenBioStat 生统爱好者周刊」运维小组:
- [
@Leslie-Lu](陆震) - [
@YihanChen325](陈奕含) - [
@kirihsia](夏鑫辛) - [
@GCRPM](徐林玉)
订阅
本周刊每周五发布,更新在微信公众号「陆震生物统计」(luzhen-biostat)上,微信搜索陆震生物统计或者扫描二维码,即可订阅。

同时,本周刊同步支持 RSS 订阅;本周刊同名中文播客现已正式在苹果播客(Apple Podcasts)和小宇宙平台上线,搜索生统爱好者周刊即可订阅收听。该播客内容基于本周刊公开内容制作,相关学术论文链接及原始资讯请查阅本周刊文字版。
(完)